DeepSeek-Prover-V1.5: Harnessing Proof Assistant Feedback for Reinforcement Learning and Monte-Carlo Tree Search
1.介绍
尽管在自然语言领域取得了显著进展,但语言模型在形式化定理证明方面仍然面临巨大挑战,例如使用 Lean(Lean 是由 Microsoft Research 开发的一个交互式定理证明器,同时也是一种依赖类型的函数式编程语言) 和 Isabelle(Isabelle 是由德国慕尼黑工业大学的 Tobias Nipkow 教授开发的通用定理证明助手,支持多种逻辑系统,包括高阶逻辑(HOL)和集合论(ZF)等),这需要严格的推导以满足验证系统的形式化规范。即使是像 GPT-4 这样的高级模型也难以应对复杂的形式化证明,这凸显了所涉及的编码和数学的复杂性。形式化定理证明模型不仅必须掌握像 Lean 定理证明器这样的形式系统的语法和语义,还必须将抽象的数学推理与精确的形式化表示结合起来。
形式化验证是一种使用数学方法来验证系统、程序或硬件设计正确性的技术。它通过自动化工具或手动方式,对系统规格说明进行逻辑推理和证明,以确保系统满足预定的安全、功能和性能要求。
形式化定理证明是一种使用计算机和形式化逻辑系统来验证数学定理和命题的方法。它涉及以下几个关键方面:
1. 形式化语言:将数学概念和定理用一种严格的、无歧义的逻辑语言表述,这种语言能够被计算机理解和处理。
2. 证明助手:使用定理证明助手(如 Lean、Isabelle、Coq 等)来自动化证明过程,这些工具提供了一套逻辑推理规则和策略,帮助用户构建和验证证明。
3. 机械验证:证明过程由计算机机械地检查,确保证明的每一步都符合逻辑规则,从而保证证明的正确性和可靠性。
4. 数学知识库:形式化定理证明通常建立在共享的数学知识库之上,如 Lean 的 mathlib,这些库包含了大量已证明的定理和引理,可供证明新定理时引用。
5. 交互式证明:用户与证明助手交互,通过应用逻辑规则和策略来构建证明,证明助手提供反馈和建议,帮助用户找到正确的证明路径。
形式化定理证明中的语言模型通常采用两种策略:证明步骤生成和整体证明生成。证明步骤生成预测每个后续策略并使用形式化验证器对其进行验证,以获取有关当前策略状态的更新信息,通常使用树搜索技术来构建有效证明。相比之下,整体证明生成具有更高的计算效率,它根据定理陈述生成完整的证明代码,需要较少的通信预算来协调证明器模型和形式化定理验证器之间的协调。
DeepSeek-Prover-V1 在 Lean 4 中通过整体证明生成取得了最先进的成果,但这种方式也带来了独特的挑战。它需要长期序列预测,而无需访问中间策略状态,而未来的策略取决于这些隐藏的结果。在 Lean 的策略模式中,证明是通过一系列转换证明状态的策略构建的。这种顺序性带来了复合错误的风险,一个误解就可能导致与有效证明路径的重大偏差。更具体地说,自回归模型在生成长证明时可能对中间策略状态产生错误的信念。
形式定理证明过程:
1. 理解题目(状态1):学生首先需要理解题目的要求和已知条件。
2. 选择证明方法(状态2):基于对题目的理解,学生选择一个合适的证明方法,比如归纳法或反证法。
3. 执行证明(状态3):学生开始执行证明,每一步都建立在前一步的基础上。
4. 验证证明(状态4):最后,学生需要验证整个证明的正确性。
错误1:错误的证明方法选择
原因:自回归模型可能会基于之前的状态(如状态1)错误地预测下一个状态(状态2)。例如,如果模型错误地认为题目更适用于归纳法,而实际上反证法更合适,那么这个错误的信念将导致整个证明过程偏离正确的路径。
影响:这会导致学生在执行证明(状态3)时遇到更多的困难,甚至可能无法完成证明。
错误2:错误的步骤执行
原因:即使证明方法选择正确,自回归模型也可能在执行具体证明步骤时产生错误的信念。例如,模型可能错误地预测下一步应该是引入某个不必要的引理,而不是直接使用已知定理。
影响:这会导致证明过程变得冗长和复杂,增加错误的风险,并可能使学生对证明的正确性产生怀疑。
错误3:错误的验证
原因:在验证证明(状态4)时,自回归模型可能错误地认为证明是正确的,即使存在逻辑漏洞或未解决的假设。
影响:这会导致学生接受一个实际上有缺陷的证明,从而影响他们对数学概念的理解和应用。
为了在证明步骤生成中无缝集成中间策略状态,同时保持整体证明生成的简单性和计算效率。DeepSeek-Prover-V1.5 中开发了一种统一的方法。该方法通过截断和恢复机制结合了证明步骤和整体证明生成技术的优势。
该过程从标准整体证明生成开始,其中语言模型按照定理语句前缀完成证明代码。然后,Lean 证明器验证此代码。如果证明正确且完整,则该过程终止。如果检测到错误,则在第一个错误消息处截断代码,并丢弃任何后续代码。然后,成功生成的证明代码将用作生成下一个证明段的提示。
为了提高模型新完成的准确性,将来自 Lean 4 证明器的最新状态作为注释附加在提示的末尾。值得注意的是,作者的方法不限于从上次成功应用的策略恢复。将截断和恢复机制集成到蒙特卡洛树搜索中,其中截断点由树搜索策略安排。
此外,提出了一种新的无奖赏探索算法,用于蒙特卡洛树搜索(MCTS) 解决证明搜索的奖励稀疏性问题。我们为树搜索agent分配内在动机,即好奇心,以广泛探索策略状态空间。这些算法模块扩展了我们的整体证明生成模型的功能,使其成为一种灵活的交互式定理证明工具,可以有效利用证明助手反馈并生成多样化的解决方案候选。
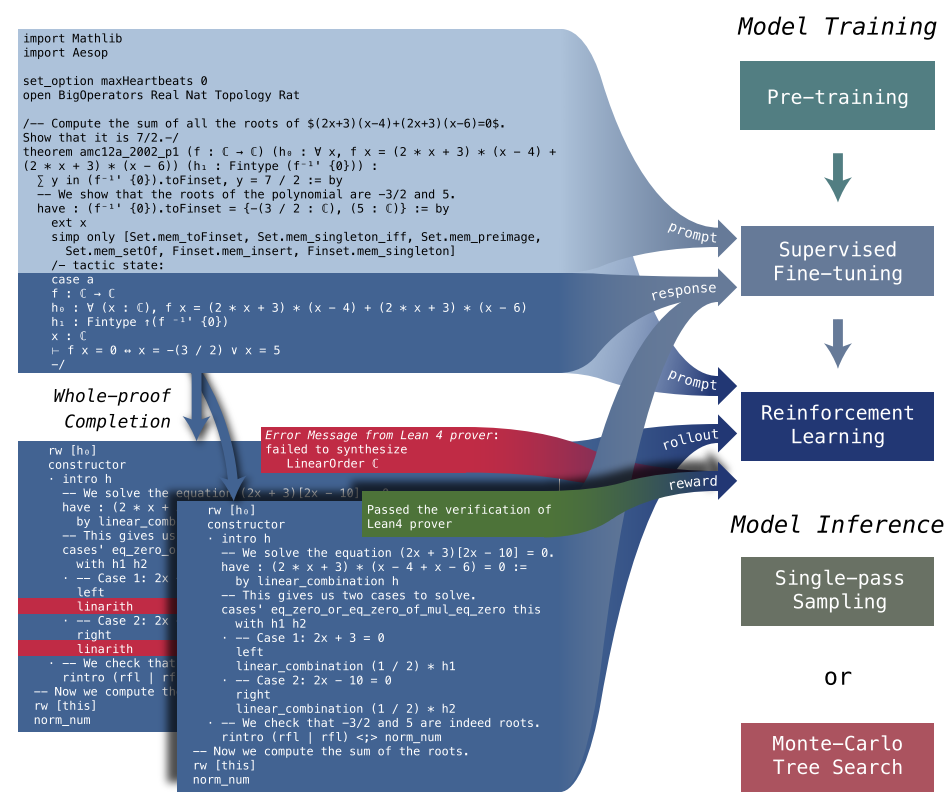
整体流程
deepseek - prove - v1.5通过预训练、监督微调和强化学习进行训练。 在监督微调期间,预训练模型接收到一个以策略状态注释关键字结尾的不完整定理证明。 训练模型预测该策略状态的内容(辅助目标)并完成后续证明步骤(主要目标)。 在强化学习阶段,给定来自Lean Prover的不完整定理证明和真实策略状态(在应用某个策略(tactic)之后,证明状态(proof state)的预期或正确结果),推出微调模型来生成多个候选证明,然后由Lean Prover验证。 这些候选者的验证结果被用作二进制(0-1)奖励,以进一步优化模型并增强其与验证系统的正式规范的一致性。 对于模型推断,提供了两种选择:单次采样和蒙特卡罗树搜索。
贡献
预训练:通过对高质量数学和代码数据进行进一步预训练来增强基础模型在形式定理证明和数学推理方面的能力,重点关注 Lean、Isabelle 和 Metamath 等形式语言。
有监督的微调:通过两种数据增强技术来改进 Lean 4 代码补全数据集。首先,使用 DeepSeek-Coder V2 236B 标注 Lean 4 代码的自然语言思维链注释,将形式定理证明与自然语言推理相结合。其次,在 Lean 4 证明代码中插入中间策略状态信息,使模型能够有效利用编译器反馈。然后使用生成的数据集来微调预训练模型。
强化学习:采用 GRPO 算法对有监督微调模型进行证明助手反馈 (RLPAF) 强化学习。Lean 证明器的验证结果作为奖赏监督,以增强模型与验证系统形式化规范的对齐性。
蒙特卡洛树搜索:通过引入一种新的抽象和相应的搜索算法,改进了形式定理证明中的树搜索方法。截断和恢复机制充当状态动作抽象,将树搜索过程无缝集成到整体证明生成框架中。提出了 RMaxTS,这是一种创新的蒙特卡洛树搜索算法,它利用 RMax 策略来解决稀疏奖赏证明搜索问题中的探索挑战。通过分配内在奖赏,该算法鼓励证明agent生成不同的规划路径,从而促进对证明空间的广泛探索。
2.模型训练
预训练
为了提高语言模型生成形式证明和通过数学语言进行推理的能力,研究者对基础模型进行了进一步预训练,这种改进涉及对高质量数据集的训练,这些数据集包括代码和自然语言数学内容。将这个改进的模型命名为 DeepSeek-ProverV1.5-Base。
监督微调
通过添加详细的解释性评论来增强来自deepseekprove - v1的证明数据集。 这种增强旨在改善自然语言描述Lean 4代码之间的一致性,从而促进更好的形式化数学推理。中间策略信息作为辅助预测任务,以支持蒙特卡洛树搜索过程中使用的截断和恢复机制。 将得到的模型称为DeepSeek-ProverV1.5-SFT。
数据管理
为有监督微调开发了一个全面的 Lean 4 代码补全数据集。该数据集包括从各种形式定理中得出的合成证明代码。这些定理来自各种项目,例如标准 Lean 4 数学库 Mathlib4、来自 DeepSeekProver-V1 和 Lean Workbook 的合成定理以及来自 miniF2F 和 ProofNet 基准的验证集。
为了扩充形式证明数据,采用了专家迭代过程。这涉及使用语言模型生成证明、验证生成的证明数据、使用验证的数据重新训练模型,然后使用优化的模型生成其他证明数据。在每次迭代之间,我们使用 DeepSeek-Coder V2 236B 将证明代码之前的思维过程标注为注释。最后,针对蒙特卡洛树搜索的截断和恢复机制定制这些数据(详见第 3.1 节)。生成的证明数据集由 9645k 个序列组成。
专家迭代过程(Expert Iteration process, ExIt)将问题分解为两个主要任务:规划(planning)和泛化(generalization)。
规划是通过树搜索来执行的,它负责在给定的状态空间中寻找最优的行动路径。这个过程涉及到对未来可能发生的情况进行模拟,并评估不同行动方案的结果。
泛化则是由深度神经网络来完成的,它的作用是从树搜索生成的策略中学习并泛化出更广泛的策略。这样,即使在未见过的状态,神经网络也能够提供合理的行动建议。
ExIt算法的关键特点是迭代过程,它包括以下几个步骤:
1. 初始化:开始时,可能没有任何先验知识,或者只有基本的策略。
2. 树搜索规划:使用树搜索来规划新的策略,这涉及到模拟和评估不同的行动方案。
3. 神经网络泛化:将树搜索的结果输入到神经网络中,让网络学习并泛化这些策略。
4. 策略改进:使用神经网络的输出来引导树搜索,从而改进和加强新的规划。
5. 迭代:重复上述过程,每次迭代都使用前一次迭代的结果来改进策略。
思想扩充证明生成
在 DeepSeek-Prover-V1 中,发现自然语言中的问题解决策略与 Lean 中的定理证明之间存在显著差距。
在自然语言中,模型会生成详细的推理步骤来构建证明,而在 Lean 中,它们通常依赖于一系列高级策略调用来强力解决问题。这些高级策略虽然有效,但却掩盖了其内部工作原理和结果,阻碍了模型使用结构化数学推理解决复杂证明目标的能力。
为了解决这个问题,开发了一种在生成定理证明代码之前结合自然语言推理的方法。与在每个证明步骤之前执行孤立的思维链推理的 Lean-STaR 类似,我们的方法将此推理直接集成为证明代码中的注释。
我们使用 DeepSeekCoder V2 236B 通过两种方式增强 DeepSeek-Prover-V1 中的现有数据:首先,在证明块的开头插入完整的自然语言解决方案;其次,交替插入与设计策略相对应的特定自然语言步骤。使用这种数据格式训练模型会强制它在证明块的开头提出完整的数学推理,并在每个策略之前提出详细的步骤规划。
这种方法成功地开发了新的行为,采用精细的数学思维来指导策略的生成。在训练数据中,使用两个不同的提示来区分 CoT(思路链)模式和非 CoT 模式以完成证明代码。(详见原pdf附录A. Illustrative Examples of Non-CoT and CoT Prompting for Proof Completion)
使用策略状态信息增强提示
为了实现蒙特卡洛树搜索的截断和恢复机制,需要从模型生成的代码中提取策略信息。使用 LeanDojo 项目中的数据提取工具增强了 Lean REPL,以三元组的形式提取策略信息,其中包括每个策略的位置以及应用之前和之后的策略状态。这些信息有助于识别触发验证错误的具体策略代码。对于生成的有效形式证明中的每个策略,将其返回的策略状态作为注释插入证明中。
训练设置
基于预训练模型进行有监督微调,并使用 2,048 的batch size和 1e-4 的恒定学习率训练 9B 个 token。训练过程从 100 个warm-up步骤开始,以稳定学习动态。训练示例被随机连接以形成序列,最大上下文长度为 4,096 个 token。
证明助手反馈的强化学习
此阶段利用 RL 根据 Lean 4 证明器的验证反馈来提高性能。
Prompts
在强化学习阶段,使用有监督微调数据集中的一组定理陈述作为RL训练的提示。选择 DeepSeekProver-V1.5-SFT 在多次尝试后生成正确证明的成功率适中的定理。这确保模型有改进空间,同时仍然能够收到积极的反馈。
经过筛选,保留了大约 4.5k 个独特的定理陈述。每个定理都以 CoT 和非 CoT 提示作为前缀,以增强模型在两种模式下的证明生成能力。
Rewards
当通过 RL 训练 LLM 时,训练好的奖赏模型通常会提供反馈信号。相比之下,形式化定理证明因为证明助手对生成的证明的严格验证,产生了显著的差异。具体来说,如果验证正确,则每个生成的证明将获得 1 的奖赏,否则将获得 0 的奖励。虽然这种二元奖赏信号是准确的,但它也很稀疏,尤其是对于那些对有监督微调模型具有挑战性的定理而言。为了缓解这种稀疏性,我们选择了对有监督微调模型具有挑战性但可实现的训练提示,如上所述。
强化学习算法
采用了群体相对策略优化 (GRPO),GRPO 为每个定理提示抽取一组候选证明,并根据组内输出的相对奖励优化模型。提示选择策略旨在尽可能在候选中包括正确和不正确的证明,这与 GRPO 的群组相对性质非常吻合,从而增强了训练过程。
训练设计
基于 SFT 模型进行强化学习训练,该模型既是初始模型,也是施加 Kullback-Leibler (KL) 散度惩罚的参考模型。使用 5e-6 的恒定学习率,KL 惩罚系数设置为 0.02。对于每个定理,抽取一组 32 个候选证明,最大长度设置为 2,048。训练batch-size配置为 512。
3.探索指向的蒙特卡罗树搜索
策略级的抽象树
为了在整体证明生成环境中实现树搜索方法,引入了证明树抽象(将形式化证明表示为一种结构化的树形结构,其中每个节点代表证明过程中的一个逻辑步骤或断言)来定义定制的状态和动作空间,并利用截断和恢复机制。
首先将不完整的证明分解为与各个证明步骤相对应的树节点序列,然后利用存储在这些树节点中的部分内容继续证明生成过程。
证明树的组成
1. 节点:每个节点代表一个逻辑断言或步骤,如假设、结论、引理等。节点可以包含逻辑公式、变量、函数等数学对象。
2. 边:边表示节点之间的逻辑关系,如推导、蕴含等。从一个节点到另一个节点的边表示前者是后者的前提或推论。
3. 根节点: 根节点通常代表证明的目标或要证明的定理。证明过程从根节点开始,逐步展开到叶子节点。
4. 叶子节点: 叶子节点代表证明的基础,如公理、定义、已知定理等。叶子节点不依赖于其他节点,是证明的起点。
截断:证明分解为树节点
在策略级构建证明搜索树,其中每条树的边代表策略状态的单个转移步骤。
首先,将模型生成的整个证明提交给Lean证明器,以将其解析为策略。
然后,在最早的验证错误处截断证明,确保所有后续策略代码都可以成功应用,以将证明推进到所需的定理。策略代码被分割成几个代码片段,每个代码片段包含一个有效的策略代码及其相关的思维链注释,对应于代表策略状态转换的单个树边。
通过这种抽象,每个策略代码被转换为一系列树节点,形成从根到特定节点的路径。
恢复:从树节点生成证明
在 Lean 4 中,不同的策略可以导致相同的策略状态,这意味着证明树中的每个节点可以对应于实现相同结果的各种策略代码。为了处理这个问题,在每个节点存储一组这些等效的策略代码。当树搜索agent展开一个节点时,它会随机选择一个策略作为语言模型的提示。此提示包括以所选策略结尾的不完整证明代码和来自 Lean 证明器的策略状态信息作为注释块。经过微调的模型经过训练,可以识别和利用这种格式,使用添加了策略状态注释的不完整代码来指导后续的证明生成。
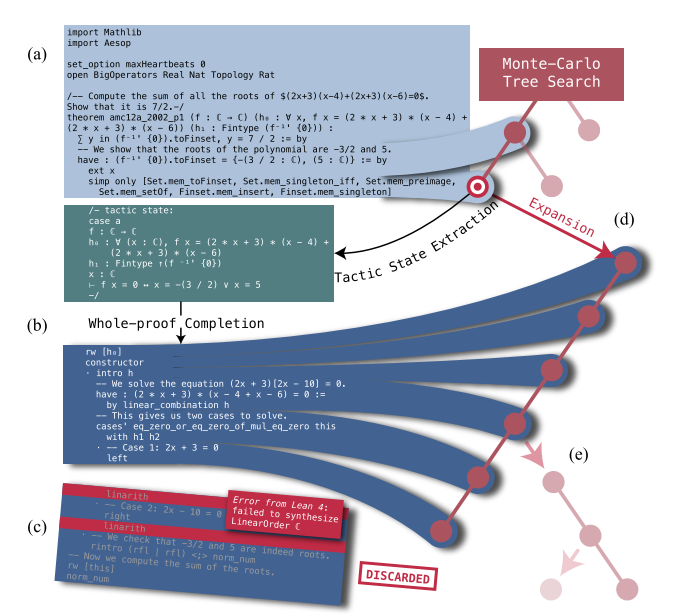
MCTS扩展步骤中的截断恢复机制。
(a)选择节点后,跟踪其对应的不完全证明码前缀,包括文件头、初始语句和来自祖先节点的成功应用策略。
(b)语言模型然后基于该前缀生成后续证明,以及包含当前策略状态的注释块。
(c)将组合的证明代码(前缀和新生成的代码)通过Lean 4证明器进行验证。如果没有发现错误,树搜索过程就会终止。如果检测到错误,我们在第一个错误消息处截断新生成的代码,丢弃后续代码,并将成功的部分解析为策略。
(d)每一种策略都作为一个新节点添加到搜索树中,在所选节点下面延伸一条后代链。
(e)一旦树更新完成,就开始下一次迭代扩展,选择一个不限于叶节点的备选节点。
这个过程不断重复,直到找到正确的证明或样本预算耗尽为止。
通过蒙特卡罗树搜索的交互式定理证明
证明搜索树是基于标准的MCTS方式开发的,迭代使用四个步骤:选择、扩展、模拟和反向传播。
作者将仿真步骤集成到扩展中,因为整体证明生成模型是从扩展节点执行rollout。
算法工作流程的详细设计如下:
选择
选择步骤,也称为树策略,从根节点开始向下遍历,目的是找到一个有潜力的节点进行扩展。这个步骤的目标是在探索(exploration)和利用(exploitation)之间取得平衡。
树节点𝑠上的树策略是通过从有效操作集中选择使值最大化的操作来计算的:
其中操作𝑎可以移动到子节点,用𝑎∈𝐶ℎ𝑖𝑙𝑑𝑟𝑒𝑛(𝑠)表示,也可以扩展当前节点𝑠,用特殊标志𝑎=⊘表示。
这种方法使用了一种称为虚拟节点的技术,它为每个节点分配一个虚拟子节点,代表当前节点 s 被选中进行扩展。这使得树搜索代理能够持续扩展非叶节点。
对节点 s 上执行动作 a 的值估计 Q_{UCB}(s,a)由两个部分组成:
其中 Q(s, a) 表示从选择历史中得出的动作值的样本估计,作为利用部分,从先前的试验中检索高价值候选。
UCB(s, a) 表示通过上置信界(UCB)计算的探索奖励,随着状态-动作对的重复执行而减少。Q_{UCB}(s, a) 代表对Q(s, a)的乐观估计,可以作为高概率的上界。
上置信界(Upper Confidence Bound,简称UCB)是一种在多臂老虎机(Multi-Armed Bandit,MAB)问题中使用的算法。这种算法旨在解决在不确定性环境下的探索(exploration)与利用(exploitation)的权衡问题。UCB算法通过为每个选项(臂)计算一个置信区间,并选择具有最高置信上界的臂来平衡探索和利用。
UCB算法的核心思想是为每个臂 a 计算一个上置信界(UCB),这个界是基于臂的平均回报和被选择的次数来计算的。算法在每个决策步骤中选择具有最高UCB值的臂,以此鼓励算法去探索那些不确定性较高(即被选择次数较少)但潜在回报可能较大的臂。
由两部分组成:
第一部分为利用(exploitation),即根据历史数据选择平均回报最高的臂。
第二部分为探索(exploration),即鼓励选择那些被选择次数较少、不确定性较高的臂。
例子:
假设一位教师(代理)负责指导学生(臂)分别学习不同的科目:数学、物理和化学。教师希望通过选择不同的教学策略(臂)来最大化学生的学习效果(奖励)。然而,教师对每种教学策略的有效性(奖励)并不完全了解,因此需要在教学过程中不断探索和调整策略。
初始化:
在开始时,教师对每种教学策略的效果都没有经验,因此可以随机选择每种策略一次,以获得初始的奖励估计。假设初始奖励如下(随机分配):
数学:2 物理:1 化学:3(表示学生的学习效果)
教师将使用UCB算法来决定在接下来的教学回合中选择哪种教学策略。
UCB_a(t)=\bar{X_a}+\sqrt{\frac{2lnt}{n_a}}
\bar{X_a}是策略 a 到时间步 t; n_a是策略 a 到时间步 t 为止被选择的总次; t 是总的决策次数。
教学阶段:
第一回合:
选择数学(随机),观察到奖励为2。
更新数学的X_数学=2和n_数学=1
第二回合:
选择物理(随机),观察到奖励为1。
更新物理的X_物理=1,n_物理=1
第三回合:
选择化学(随机),观察到奖励为3
更新化学的X_化学=3,n_化学=1
第4回合(开始应用UCB):
计算每个科目的UCB值:数学=4 物理=3 化学=5
选择化学因为它的UCB值更高。
第五回合
选择化学,观察到奖励为3
更新化学的X_化学=(3+3)/2=3,n_化学=2
第六回合:
再次计算UCB:数学=3.82 物理=2.82 化学=3.91
再次选择化学
扩展
下一步是调用证明生成模型来扩展选择阶段指定的节点。
执行全证明生成:恢复存储在指定扩容节点上的不完整证明码,进行完整证明生成,提出一系列后续策略,并将生成的证明提交给Lean进行验证。 这样的验证完成试验相当于在标准MCTS框架内进行一次模拟rollout。
验证结果处理:如果验证结果表明证明是完整的,那么搜索过程就可以终止,因为我们已经找到了所需定理的新证明。如果证明不完整或存在错误,我们需要解析验证反馈,并在最早的验证错误处截断生成的证明。
错误处理和节点转换:将剩余的策略(tactics)转换为一系列节点,这些节点将被合并到搜索树中。这一步是将不完整证明中的错误部分转换为搜索树中的路径,以便后续可以继续探索。
全证明生成设置:由于使用的是全证明生成设置,输出是包含一系列策略的完整证明,而不仅仅是下一个策略。这意味着在每次迭代中,扩展过程可能会将一系列树节点路径插入到搜索树中,而不仅仅是扩展一层子节点。这种扩展过程与传统的为竞争游戏设计的MCTS不同。
反向传播
每个树搜索迭代的最后阶段是沿着从根到扩展节点的选择轨迹更新值统计信息,即更新与TreePolicy(s)中所述的树策略相关的值。
设\tau=\{(root,s^{(1)}),(s^{(1)},s^{(2)}),(s^{(2)},s^{(3)}),...,(s^{(|\tau|-1)}=s_t,\oslash)\}表示以𝑠𝑡为展开节点结束的𝑡次迭代选择轨迹。
奖励的外在来源来自于编译器的反馈,对于完成的证明,奖励为R_{内}(\tau)=1,对于未完成的证明,奖励为R_{内}(\tau)=0。
蒙特卡洛树搜索的内在奖励
在形式定理证明的搜索问题中,外在奖励是极其稀疏的,即只有当证明完全解出时,搜索代理才能获得非零奖励。 更具体地说,证明搜索过程形成了一个树形结构,只有一组狭窄的叶子提供非零奖励。
为了促进对稀疏奖励序列决策的探索,一个经典的方法是构建内在奖励,它鼓励agent不仅优化外在奖励,而且获取有关交互环境的一般信息。 在本节中,介绍了内在奖励驱动的探索算法,RMax应用于树搜索(RMaxTS),将无奖励探索纳入证明搜索问题。
RMax应用于树搜索
RMax算法可以在多项式时间内达到近似最优的平均奖励。RMax算法特别适用于随机博弈和马尔可夫决策过程(MDPs)。该算法的核心思想是维护一个完整但可能不准确的环境模型,并根据这个模型导出的最优策略来行动。模型以乐观的方式初始化:所有状态的所有动作都返回最大可能的奖励。
初始化:
构建一个包含多个阶段游戏的模型 M' ,每个阶段游戏对应一个真实游戏,以及一个额外的虚构游戏 G_0 。
初始化所有游戏矩阵,使其在所有条目中都有 (R_{max},0)。
初始化从任何游戏 G_i 到虚构游戏 G_0 的转移概率 P(G_i,G_0,a,a')=1 。
重复执行以下步骤:
计算和行动:计算当前状态下的最优 T -步策略,并执行 T 步或直到一个新的条目变得已知。
观察和更新:在每次联合行动后,根据观察更新与该行动相关的奖励和达到的状态集合。如果从某个条目达到的状态集合包含足够多的元素(根据特定的统计阈值),则将此条目标记为已知,并根据观察到的频率更新此条目的转移概率。
用教师学生举个例子:
1. 教师开始时对学生的潜力持乐观态度,假设通过任何教学方法都能达到最好的学习效果(即获得最大奖励)。这相当于 RMax 算法中的乐观初始化,所有状态和动作都被赋予最大可能的奖励。
2. 探索与尝试:教师尝试不同的教学方法(如讲解、练习、讨论等),并观察学生的反馈和学习进度。在 RMax 算法中,这对应于计算和执行最优策略,同时探索未知的策略空间。
3. 观察与更新:根据学生的反馈,教师更新对不同教学方法效果的认识。例如,如果发现某个方法特别有效,教师会调整对该方法的预期,认为它更可能带来好的结果。在 RMax 算法中,这对应于观察和更新步骤,根据实际结果更新环境模型。
4. 调整策略:教师根据更新后的预期调整教学策略,更多地采用那些被证明有效的方法。在 RMax 算法中,这涉及到根据更新的环境模型重新计算最优策略。
5. 重复过程:教师不断重复探索、观察和调整的过程,直到找到最有效的教学策略。在 RMax 算法中,这个过程会重复进行,直到达到近似最优的策略或探索时间结束
RMax的核心思想是探索广泛覆盖的状态空间。 agent在达到一个未见过的状态时给予自己最大的奖励。 在证明搜索的背景下,在证明完成之前不提供外部奖励,算法过程类似于ZeroRMax (Jin et al., 2020),其中智能体的探索仅由内在奖励驱动,即设置R(\tau)=R_{内}(\tau)。 树扩展步骤的内在奖励取决于是否向搜索树中添加新节点,
\tau表示需要对反向传播进行奖励分配的最近的选择轨迹。这种探索策略优先扩展那些由证明模型生成的策略导致多样化策略状态的节点。由于多个Lean代码可能导致相同的中间状态转换,这种启发式方法可以潜在地减少冗余生成并提高样本效率。
非平稳奖励的UCB
对于蒙特卡罗树搜索,常用的UCB1探索奖励设置是使用:
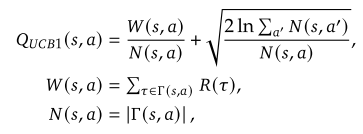
W(s, a) 是动作 a 在状态 s 下的累积奖励。N(s, a) 是动作 a 在状态 s 下被选择的次数。\Gamma(s, a) 是包含 (s, a) 作为中间选择步骤的树策略轨迹列表。
在实际应用中,尤其是在复杂的探索环境中,奖励信号可能是非固定的。这意味着随着探索的深入,发现新节点(带有未见过的策略状态)的难度会增加,从而导致奖励信号的预期值随着探索的进展而衰减。
为了解决非固定奖励问题,文中提出了使用折扣上置信界(DUCB)算法。DUCB算法通过引入一个折扣因子 \gamma (其中 \gamma \in(0,1) )来平滑地降低过时的反馈记录的权重。
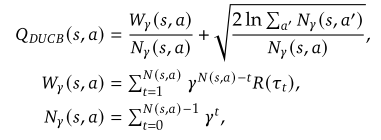
W_{\gamma}(s,a)是考虑折扣因子的累计奖励。N_{\gamma}(s,a)是考虑折扣因子的动作选择次数。折扣因子\gamma 的作用是为新近收到的反馈分配更大的权重,从而更好地反映当前的探索状态。折扣应用于树搜索迭代,而不是单个轨迹内的动作-步骤。
蒙特卡罗树搜索的并行化
为了提高蒙特卡罗树搜索(MCTS)的效率,实现了Chaslot等人(2008)描述的几种已建立的并行化技术。
根并行化:在每个节点部署256个MCTS运行程序,每个GPU使用一种语言模型,批处理大小为512个用于生成证明。 Lean通过REPL调用,并在具有数千个CPU内核的集群上执行,其中每个证明验证任务由单个进程处理,在沙盒中创建和终止。 语言模型的证明生成和精益证明器的验证都是异步处理的。 这种设置允许MCTS运行程序执行并发树搜索操作,大大加快了进程。
树并行化:用32个线程来管理每个搜索树,以并行化树的迭代步骤。 该方法有效地安排和平衡了证明生成和Lean验证的任务。 每个线程工作者迭代地执行树搜索循环,选择一个候选节点进行扩展,调用语言模型生成证明,用Lean证明器验证生成的证明,并执行反向传播。
虚拟损失:为了鼓励并发线程选择不同的节点,我们为正在进行的迭代分配一个虚拟奖励𝑅(τ)= 0。 这涉及到临时反向传播奖励0,并在完成后将其更新为真实奖励。 这种策略促进了对不同节点的探索进行扩展,从而提高了整体搜索效率。
与现有方法的比较
在形式数学证明搜索中使用语言模型的方法通常有两种主要策略:
多通道证明步骤生成:该策略将证明过程分解为策略生成和验证的多个片段,通常遵循树搜索模式。 它包括一次生成和验证一个策略,重复下一个策略的过程,直到没有证据目标。
单次整体证明生成:这种方法在一次尝试中生成并验证整个证明。 如果证明不正确,则模型在下一次尝试中生成新的证明。
本文证明树搜索方法独特地连接了这两种策略,提供了一种新颖的混合方法。 它从全证明生成开始,类似于单遍方法,但通过实现复杂的截断和恢复机制扩展了这一点。 该过程包括将生成的证明截断为其成功的初始片段,将该片段解析为单个策略,并从该点开始恢复树搜索。 这种迭代过程有效地实现了蒙特卡罗树搜索,无缝地集成了单次完整证明生成与多次证明步骤生成。
因此,可以训练一个具有几乎相同目标的单一模型,以同时支持两种策略。 实验结果表明,这种统一的方法在两种设置下都取得了优异的性能。