论文题目:Grounded Chain-of-Thought for Multimodal Large Language Models
发表期刊:2025 The IEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR) (CCF-A)
论文作者:Qiong Wu, Xiangcong Yang, Yiyi Zhou, Chenxin Fang, Baiyang Song, Xiaoshuai Sun, Rongrong Ji
作者单位:厦门大学-多媒体可信感知与高效计算教育部重点实验室
1. 背景
1.1 问题
多模态大语言模型(MLLMs)在视觉-语言任务中取得了显著进展,但在理解图像时很容易出现“视觉幻觉”(visual hallucination)。视觉幻觉的一种表现是模型对图像理解不足,导致回答错误;另一种更微妙的表现是,MLLM 即使给出了正确的答案,但其推理并非基于图像中的相关视觉信息,而是依赖于数据分布偏差,这导致模型的可靠性受到质疑。这种视觉幻觉问题不仅影响模型在视觉问答(VQA)任务中的表现,还可能导致在实际应用中的潜在风险。
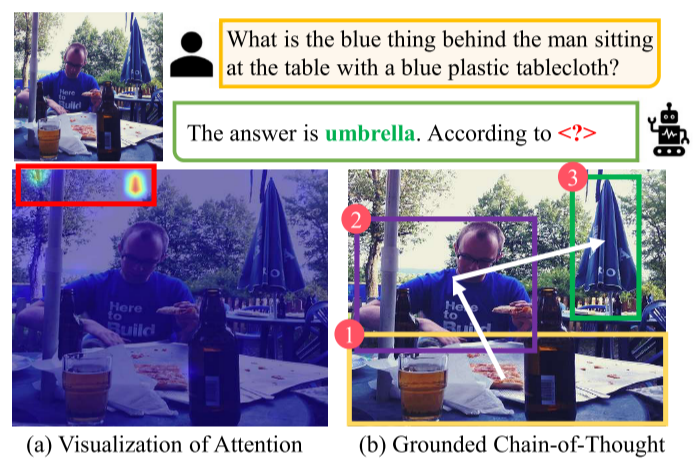
常规问题a与提出的方法b对比。MLLM虽然可以给出正确的内容,但是这与其注意力热图中内容并不统一。
1.2 本文贡献
为了解决上述问题,作者从视觉空间推理的角度出发,提出了一个新的学习任务,称为 Grounded Chain-of-Thought (GCoT)。
传统的视觉 CoT (visual CoT) 研究更侧重于视觉知识推理。
GCoT 则旨在帮助 MLLMs 逐步识别并“ground”(定位)相关的视觉线索。
通过这个过程,模型在预测正确答案时,能以图像中的定位坐标(grounding coordinates)作为直观依据。
为了支持 GCoT 任务的研究和训练,作者精心设计并构建了一个名为 multimodal grounded chain-of-thought (MM-GCoT) 的数据集。
论文还引入了一个包括:
Answer Accuracy: 回答的准确性。
Grounding Accuracy: 定位的准确性。
Answer-Grounding Consistency: 回答与定位之间的一致性,即模型回答正确时,是否也定位到了图中正确的区域。
的评估系统,用于衡量 MLLMs 在 GCoT 任务上的表现和视觉幻觉程度。
实验与发现:
作者在 12 个先进的 MLLMs 上进行了一系列实验,并得出了一些重要发现:
大多数 MLLMs 在一致性评估(consistency evaluation)上表现很差,这表明它们存在明显的视觉幻觉。
视觉幻觉问题与模型的参数规模和整体多模态性能没有直接关系。换句话说,更大、更强的 MLLM 并不会受到更小的影响。
数据集的效果:
实验表明,使用提出的 MM-GCoT 数据集进行训练,可以帮助现有 MLLMs 很好地培养 GCoT 能力,并显著减少不一致的回答( inconsistent answering)。
泛化能力:
模型获得的 GCoT 能力还可以泛化到现有的多模态任务上,例如开放领域问答(open-world QA)和指代表达理解(REC)。

相关视觉语言任务(a-d)和作者的方法之间的比较。(a)在边框输出方面与我们的GCoT类似,但它仅用于检测标题中提到的实例。与GCoT相比,Grounded QA(c)缺乏隐藏的推理步骤。VCoT(d)通过提供更详细的回答思想扩展了MLLM(B)的common VQA,其更多地涉及知识推理。相比之下,GCoT旨在将问题分解为具有接地信息的多个任务步骤,为MLLM的视觉空间推理提供直观的基础。
2. Grounded Chain-of-Thought
给定一个问题和一幅图像,GCoT将首先让MLLM对任务进行分析和分解,然后对每个任务步骤进行推理,并提供图像中任务相关元素的空间信息。基于这些边界框的推理步骤,MLLM将预测答案并提供空间坐标作为视觉的基础。在这种情况下,可以看到,GCoT将MLLM的直接回答转换为多步决策过程:
其中I,T代表输入的图像和文字;A代表最终的答案;R_t,G_t代表在t步时的视觉证据和文本推理状态。
3. MM-GCoT: 新的多模态数据集
3.1 数据集信息
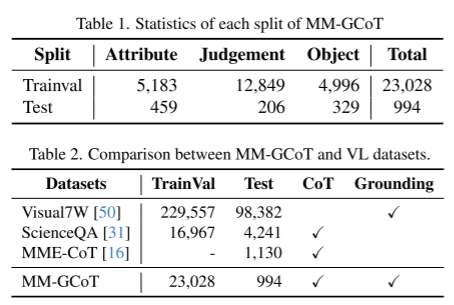
为了促进GCoT的研究,作者设计并构建了一个大型的MLLM SFT数据集MM-GCoT。MM-GCoT是唯一一个将边界框与CoT相结合的数据集。
所有样本被分为三类,即Attribute、Judgement和Object。在这里,Attribute是指在查询目标的具体属性时,提供对象的类型和位置的问题。Judgement是对给定描述的正确性进行检验,而Object是重点识别指定位置上的对象类别的问题。

3.2 数据集构建
MM-GCoT的构建遵循严格的四阶段方法:
首先使用IoU方法将区域描述与Visual Genome中的对象注释对齐,当一个对象只有一个区域的IoU满足阈值时,我们认为它们是匹配的。
使用匹配的对象作为节点,构建一个基于空间和语义关系的空间关系图。为了生成多步推理链,迭代地从这个图中采样关系路径。
使用结构化模板来收集边界盒坐标,对象属性和上下文关系的信息。
应用LLM将模板翻译成流畅的自然语言问题。
3.3 评估指标
在MM-GCoT评价方面,主要考虑对MLLM的幻视评价,因为现有的MLLM在没有准确微调的情况下很难产生GCoT输出。在这种情况下,只关注最终答案的一致性。
作者使用了三个关键指标:答案准确性(A-Acc)、边框准确性(G-Acc)和答案-边框一致性(Consist)。
A-Acc在预测和实际答案之间采用文本匹配,而G-Acc使用Acc@0.5作为度量,要求预测和实际框之间的IoU > 0.5。答案基础一致性度量由Con.=\frac{|S_{ca,cb}|}{|S_{ca,cb}|+|S_{ca,wb}|+|S_{wa,cb}|}得到。|S_{ca,cb}|,|S_{ca,wb}|,|S_{wa,cb}| 分别代表具有正确答案和正确框、正确答案和错误框以及错误答案和正确框的样本集。
3.4 现有MLLM的评估设置
大多数现有的MLLM能够进行视觉边界预测,但它们仍然难以直接输出具有边框信息的答案。在这种情况下,作者设计了两种激励策略来激发他们的基础问答能力。
第一种解决方案是答案优先提示,它要求模型首先提供答案,然后给出答案坐标。
第二种是边框先行提示。它让MLLM首先框出潜在的答案,然后基于此回答问题。
在两个设置方面,答案优先的设置相对容易,因为MLLM是检测答案实例。该边框可以检查MLLM是否真正看到图像中的答案提示。另一个接地优先的方法更具挑战性,但也接近幻觉评估的目标。它可以检查MLLM是否找到关键视觉元素,并根据它回答问题。所有被检查的MLLM将报告上述三个指标在这两个设置。
4 实验&结论
实验结果揭示了以下关键结论:
现有MLLMs普遍存在视觉幻觉问题
表现不佳的一致性:大多数MLLMs在答案-定位一致性(Consistency)评估中表现不佳,表明它们的答案与实际关注的视觉线索之间存在显著差异。例如,LLaVA-OneVision-72B在答案优先(Answer-First)提示设置下,一致性仅为11.1%,尽管其平均答案准确率(A-Acc)达到75.7%。
视觉幻觉的普遍性:即使是性能最先进的模型(如InternVL2.5-78B),在一致性评估中也仅达到35.4%的平均表现,显示出明显的视觉幻觉问题。
视觉幻觉与模型规模无关

Qwen2.5-VL和InternVL2.5模型分别在回答优先和边框优先假设下不同参数尺度的结果可视化。蓝色、红色和绿色边界框分别表示来自基本尺度模型(Qwen2.5 VL-7 B和InternVL2.5- 38 B)、大尺度模型(Qwen2.5-VL-72 B和InternVL2.5- 78 B)和实际边框的预测。这些可视化显示超大MLLM在对比度上表现出较差的一致性。
模型规模与幻觉的关系:实验结果表明,视觉幻觉问题与模型的规模(参数数量)没有直接关系。例如,Qwen2.5-VL系列模型从3B到7B再到72B,答案准确率仅分别提高了1.3%和1.9%,而一致性表现甚至在7B版本中优于72B版本(Qwen2.5-VL-7B的一致性为59.8%,而72B版本为41.6%)。
小模型可能表现更好:在某些情况下,较小的模型可能在一致性方面表现更好。例如,InternVL2.5-38B在“Object”任务中的一致性为38.9%,而其更大的版本InternVL2.5-78B仅为37.0%。
GCoT训练显著提升模型性能
一致性显著提升:通过在MM-GCoT数据集上进行训练,MLLMs的视觉空间推理能力和一致性得到了显著提升。例如,LLaVA-7B经过GCoT训练后,答案准确率提高了4.5%,一致性提高了55.7%;LLaVA-13B GCoT在多个指标上均优于或接近Qwen2.5-VL-7B-Instruct。
视觉理解的增强:GCoT训练不仅提升了模型的一致性,还显著增强了模型对视觉信息的理解和利用能力。例如,LLaVA-13B GCoT在定位准确率(G-Acc)上仅提高了2.2%,但一致性提高了61.2%,表明其主要通过增强视觉理解来提升性能。
不同任务类型的表现差异
“Attribute”任务:在“Attribute”任务中,模型的定位准确率(G-Acc)最高,例如Qwen2.5-VL-7B在定位优先(Grounding-First)提示设置下达到了82.6%的定位准确率。这表明,当问题中包含明确的空间关系描述时,模型更容易进行准确的视觉定位。
“Judgement”任务:模型在“Judgement”任务中答案准确率(A-Acc)最高,平均达到86.1%。这表明,对于事实验证类问题,MLLMs更容易给出正确答案,但这种高准确率并不一定基于正确的视觉证据。
“Object”任务:模型在“Object”任务中表现出最强的答案-定位一致性,例如InternVL2.5-8B达到了39.4%的一致性。这表明,当模型成功识别目标对象时,能够更好地利用视觉区域生成一致的回答。
不同提示策略的影响
答案优先(Answer-First):在这种提示策略下,模型通常表现出更高的答案准确率,但定位准确率和一致性较低。例如,LLaVA-7B在答案优先设置下的答案准确率为68.6%,而定位准确率仅为9.2%。
定位优先(Grounding-First):在这种提示策略下,模型的定位准确率有所提高,但答案准确率显著下降。例如,LLaVA-7B在定位优先设置下的定位准确率为6.3%,但答案准确率仅为59.7%。这表明,模型在没有正确视觉证据的情况下,仍可能生成正确答案,但这种答案的可靠性较低。
GCoT训练的泛化能力
跨任务泛化:经过GCoT训练的模型不仅在GCoT任务上表现出色,还能将这种能力迁移到其他多模态任务中,如开放世界问答(open-world QA)和引用表达理解(REC)。例如,LLaVA-1.5 13B GCoT在这些任务中也表现出良好的性能,能够提供详细的视觉证据支持其推理过程。
小模型的高效性:即使在参数较少的情况下(如LLaVA-1.5 13B GCoT),经过GCoT训练的模型也能在复杂任务中表现出色,显示出高效利用视觉信息的能力。