论文题目:Retentive Network: A Successor to Transformer for Large Language Models
发表时间:2023 IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING (影响因子:8.9)
论文作者:Jianxin Li , Hao Peng , Yuwei Cao , Yingtong Dou, Hekai Zhang, Philip S. Yu and Lifang He.
作者单位:北京航空航天大学,美国伊利诺斯大学、燕山大学、美国利哈伊大学。
1.背景
1.1 介绍
目前图神经网络在以网络表示学习中被广泛采用,并且在节点分类、聚类和可视化等任务中表现出色。例如图卷积网络(GCN)和图注意力网络(GAT)。
尽管现有的一些方法考虑了现实世界网络的异构性,但异构性问题尚未得到充分解决。这些方法要么局限于元路径,无法完全捕捉节点间的语义相似性(许多现有的方法在处理异构图时,主要依赖于元路径来定义不同类型节点之间的语义关系。元路径是指定类型的节点序列,它们通过边连接,表示一种特定的语义关系。然而,这种方法的局限性在于,元路径可能无法完全捕捉节点之间的所有语义相似性,因为它们只能表示简单的、线性的关系,而不能表达更复杂的、非线性的或者多跳的关系。);要么使用复杂的神经网络技术。
概念定义:
异构图信息网络(HIN):HIN是指包含不同类型的节点和边的网络。在这种网络中,不同类型的节点和边携带着不同的语义信息,这使得网络的语义更加丰富但也更复杂。
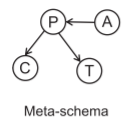
元模式(Meta-Schema):元模式是定义在HIN上的一个概念,它是一个有向图,用来描述网络中的节点类型和边类型。元模式为理解和操作HIN提供了一个框架。
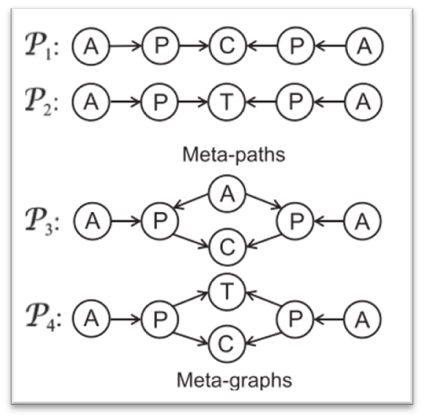
元路径(Meta-Path):元路径是在元模式上定义的一条路径,它指定了一种复合关系,用于描述不同类型节点之间的语义关系。例如,在引用网络DBLP中,元路径P1可以定义为两个作者如果在同一会议发表论文,则它们是相似的。
元图(Meta-Graph):元图是在元模式上定义的有向无环图(DAG),它包含单个源节点和单个汇节点。元图可以捕捉比元路径更复杂的语义关系。例如,元图P3不仅要求两个作者在同一会议发表论文,还要求他们与同一个第三作者合作,这样才能认为这两个作者是相似的。
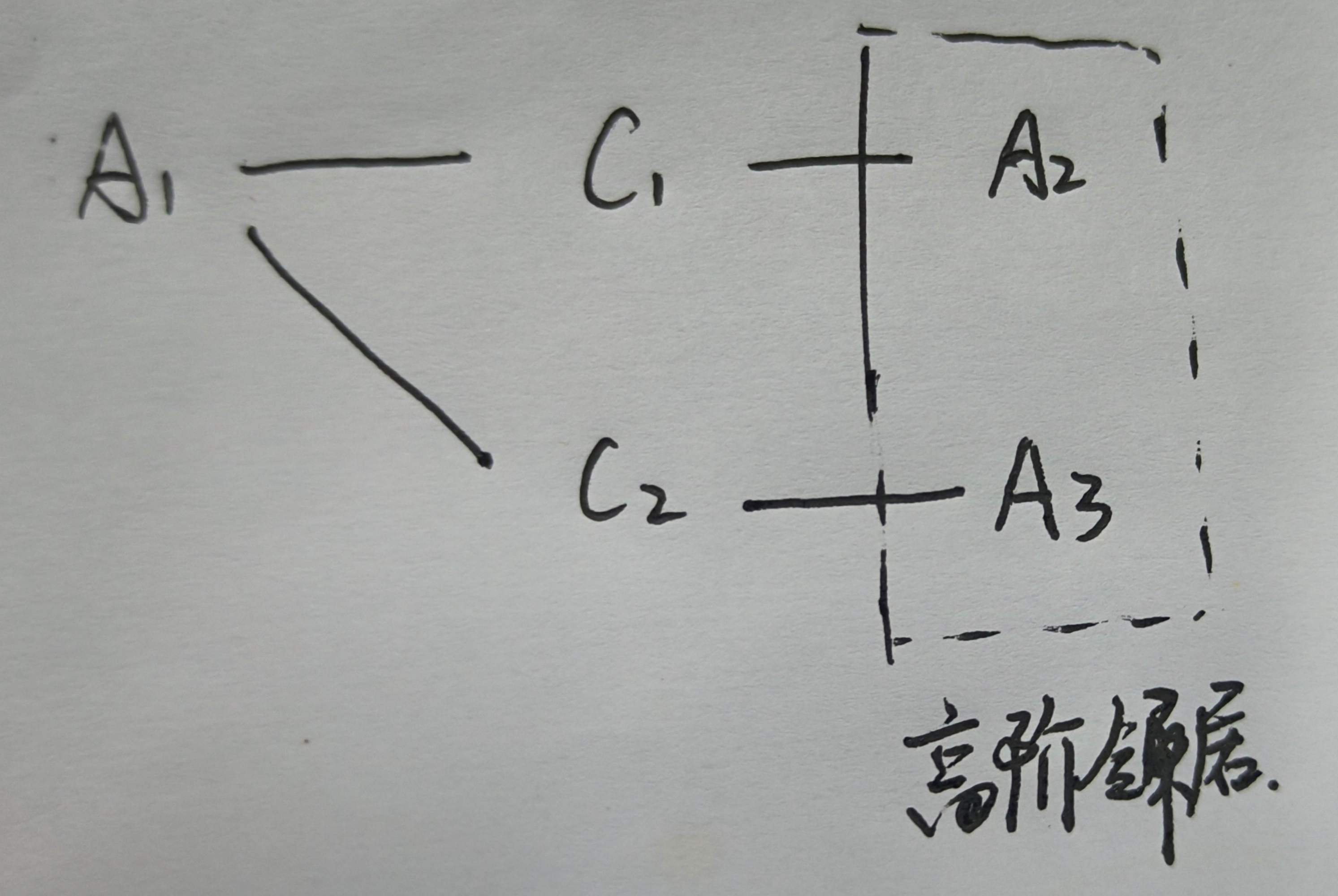
直接邻居和高阶邻居:直接邻居是指通过元路径或元图直接与给定节点相连的节点。而高阶邻居则是指那些与给定节点没有直接连接,但通过共享一些基于元路径或元图的共同邻居而相互关联的节点。以DBLP数据集为例,假设有两个作者a1和a2在同一会议c1发表论文,而a1和另一个作者a3在另一个会议c2发表论文。根据元路径P1,a2和a3都是a1的邻居。尽管a2和a3之间没有直接的联系,但它们仍然通过a1相互关联,因此它们被视为高阶邻居。
A、P、C和T分别代表作者、论文、会议和关键词(或专业术语)
本文提出的两个现有问题:
异构图的语义捕捉问题:
现有的图神经网络方法在处理异构图时,往往只依赖于元路径来捕捉节点间的语义相似性,这限制了模型捕捉基于内容的节点相似性的能力。元路径虽然能够定义节点间的简单关系,但无法充分捕捉节点间更复杂的语义关系。此外,现有方法很少利用元图,而元图能够提供比元路径更丰富的语义信息。
节点间内容相关性捕捉问题:
现有方法在不同程度上忽略了节点与其高阶邻居之间的内容相关性。这些方法通常只关注节点与其直接邻居之间的关系,而没有考虑非直接连接的节点(即高阶邻居)之间的相关性。这种忽略限制了模型捕捉基于内容的节点间相互依赖性的能力,特别是在考虑节点的一阶、二阶以及更高阶邻居时。
1.2 本文结果
本文提出了以下框架和方法:
1. Higher-order Attribute-Enhancing Framework (HAE)
HAE框架:HAE框架通过堆叠多个语义基础的卷积层(Semantic-based Convolutional Layers, SCLs)和基于内容的自注意力层(Content-based Self-Attention Layers, CALs),来逐步增强输入节点特征的语义和基于内容的交互。
2. Semantic-Based Convolutional Layer (SCL)
SCL功能:SCL用于增强输入节点特征的语义信息。它结合了多个元路径和元图,以捕获其中的丰富异构语义。
元路径和元图:这些元路径和元图需要以相同的节点类型(目标类型)开始和结束。每个元路径/元图都与一个可训练的权重相关联,这些权重允许模型更关注更重要的元路径/元图。
相似性定义:基于元路径/元图实例,定义了两个目标节点之间的相似性,这种相似性由元路径/元图的权重参数化。
邻接矩阵构建:构建一个由所有目标节点对之间相似性组成的邻接矩阵,将原始异构图转换为具有加权连接的目标节点之间的同构图。
图卷积应用:在转换后的网络上应用图卷积,使SCL能够将输入节点特征与有意义的语义信息融合。
3. Content-Based Self-Attention Layer (CAL)
CAL功能:CAL利用节点与其邻居之间的基于内容的交互来增强节点嵌入。
二进制邻接矩阵:基于元路径/元图的连接构建二进制邻接矩阵,定义转换后的同构图。
自注意力机制:利用自注意力机制计算每个节点的隐藏表示,通过关注其邻居来实现。这里使用的是基于内容的注意力,而不是基于位置的注意力,即注意力分数取决于节点-邻居对的表示,而在应用注意力时不区分邻居的顺序。
4. HAE框架的灵活性
堆叠顺序:HAE框架允许以任意顺序堆叠任意数量的SCL和CAL,提供了更多的灵活性,用户可以根据任务需求组织构建块。
HAEGNN结构:HAEGNN特别由一个SCL后跟多个CAL组成。这种设计是因为在计算机视觉领域的研究表明,自注意力在后期层和卷积层之后使用时特别有效。
2. 概念公式定义
1. 异构信息网络
异构信息网络定义为G=(V,E),其中V和E代表各种类型的节点和边的集合。
例如,DBLP数据集是HIN。它包含多种类型的节点,包括作者,论文,会议和术语(关键字)。它还包含不同类型的边(关系),如作者与论文之间的发布关系,论文与会议之间的发布关系,以及论文与术语之间的关系。
2.元模式
给定一个HIN G=(V,E),其元模式 T_G=(L,R)是一个有向图,定义在 L(G中的节点类型)和 R(G中的边类型)上。
例如,下图显示了DBLP数据集的元模式,这是一个总结了数据集中所有节点类型和边类型的有向图。
3.元路径
给定一个元模式T_G=(L,R),一个元路径 P,表示为 L1→R1L2→R2…→Rk−1Lk,是在 T_G上定义的一种复合关系 R=R1∘R2∘…∘Rk−1R=R1∘R2∘…∘Rk−1 的路径,其中 ∘是关系组合操作符。
如果路径 p=v1→v2→…→vk 在网络 G中遵循元路径 P,并且对于所有的 i,vi是类型 Li的节点,我们就说这个路径 p是元路径 P的一个实例。
例如:在图中的 P1是在DBLP数据集的元模式上定义的一个元路径。P1定义了作者节点之间的关系。如果 a1-p1-c1-p2-a2是 P1的一个实例,这表明作者 a1和 a2是相似的,因为他们在同一个会议 c1发表了他们的作品 p1和 p2。
4.元图
给定一个元模式T_G=(L,R),一个元图 M是一个有向无环图,具有单个源节点和单个汇聚节点。M中的节点和边分别限制在 L和 R中。
定义元图实例的方式与定义元路径实例的方式相同。
例如,在图中的 P4是在DBLP数据集的元模式上定义的一个元图。与元路径 P1类似,P4也定义了作者节点之间的关系。然而,P4传达了比 P1更丰富和更复杂的语义。如果 a1-p1-c1(t1)-p2-a2 是 P4的一个实例,它表明作者 a1和 a2是相似的,因为他们在同一个会议 c1发表了他们的作品 p1和 p2,并且 p1和 p2共享相同的关键词 t1。
在这项研究中,元路径和元图被统称为语义结构。这种统称是因为它们都用于捕捉和表达异构图中的复杂语义关系。
为了简化表示,语义结构通过其组成节点类型来表示。例如,如果一个元路径或元图涉及作者(A)、论文(P)、会议(C)和关键词(T),则可以使用这些节点类型的缩写来表示特定的元路径或元图。
如图中的元路径P1被表示为APCPA,这表示该元路径从作者(A)开始,通过论文(P)到会议(C),再通过另一篇论文(P)回到作者(A)。另一个元图P3被表示为APA(C)PA,这表示该元图从作者(A)开始,通过论文(P)到会议(C),然后通过会议中的关键词(T)连接到另一篇论文(P),最后回到作者(A)。
3. 方法
本文提出方法的整体架构如图,HAEGNN包含三个组件,即,(a)基于语义的卷积层(SCL),(B)基于内容的自注意层(CAL),以及(c)高阶属性增强框架(HAE)。模型的输入是初始特征,例如与节点相关的关键字的BOW表示。(BOW表示Bag-of-Words是一种简单的方式来表示文本数据,它计算每个词在文档集合中出现的次数或频率。)
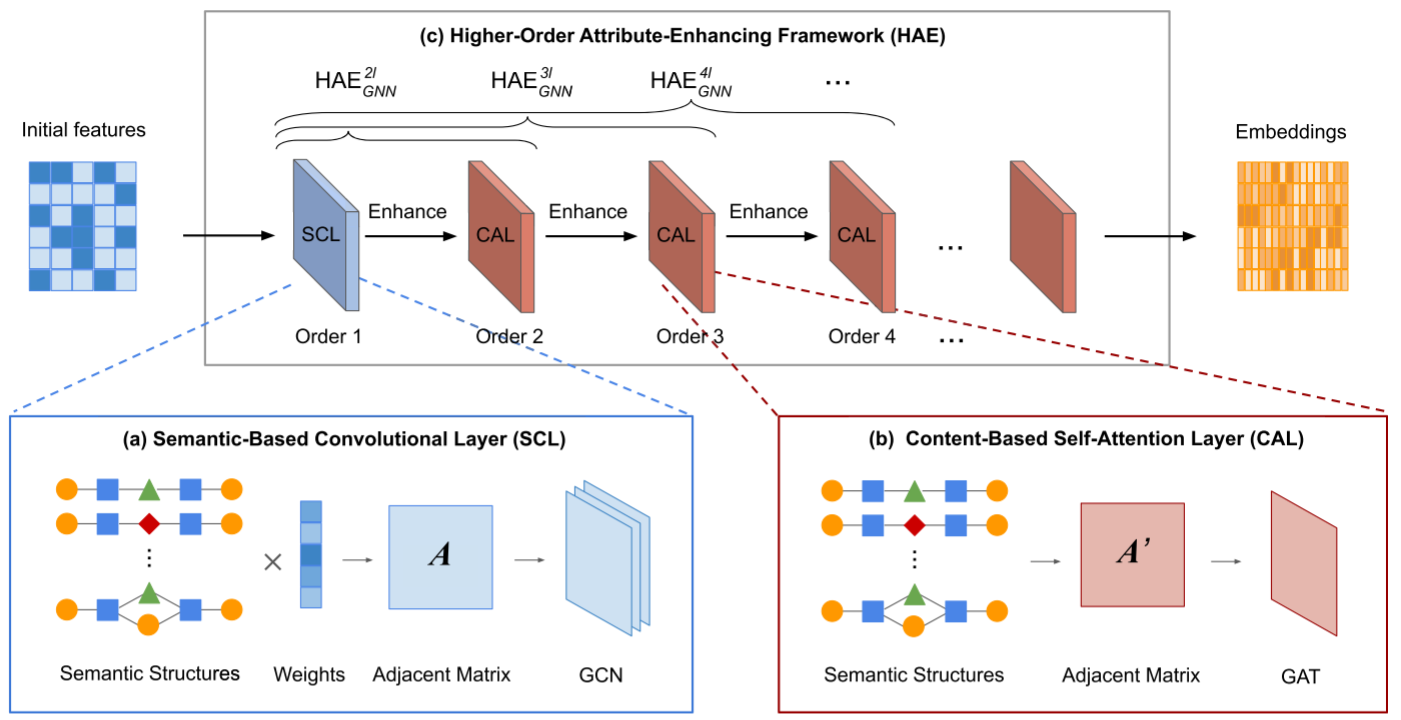
3.1 基于语义的卷积层SCL
SCL通过包含在多个元路径和元图中的丰富语义增强了输入节点特征。具体地,对于每对目标节点,SCL测量这两个组件节点之间的基于多语义结构的相似性。相似度由所有语义结构的权重参数化。通过这种方式,SCL构造了一个相邻矩阵,在图中表示为A,该矩阵包含所有目标节点之间的相似性。之后,SCL利用卷积结构根据目标节点的相似性融合它们的嵌入。因此,SCL在语义上接近的节点也具有类似嵌入的意义上学习语义。
对元路径:
首先,通过交换矩阵使用单个元路径计算两个节点之间的相似度。对给定的元路径P=L_1L_2...L_k,它的交换矩阵为C_P=W_{L_1L_2}·W_{L_2L_3}·...·W_{L_{k-1}L_k},其中W_{L_iL_j}是Li型和Lj型节点之间的邻接矩阵,对于元路径 P1=APCPA,其交换矩阵 CP1可以通过邻接矩阵的乘积来计算,具体的计算公式为 C_{P_1}=W_{AP}·W_{PC}·W_{CP}·W_{PA}=W_{AP}·W_{PC}·W_{PC}^T·W_{AP}^T,对给定的Cp,每个元素C_P(i,j)代表在元路径P下节点v_{1i} \in L_1和节点v_{kj} \in L_k的元路径实例计数。
元路径实例的数量越大,表示两个节点之间的联系越紧密,因此 C_P(i,j)揭示了v_{1i} 和 v_{kj} 之间的相似度。
对元图:
对元图的结构复杂,与元路径相似,利用交换矩阵计算。给定一个元图,把一个元图作为多个元路径的合成。对每个组成元路径,将其交换矩阵表示为邻接矩阵之间的乘法序列。然后,合并所有组件元路径的乘法序列以获得交换路径,并且还利用了hadamard乘积,当子序列不同时,对组合逐元素乘积。
例如,元图 P3=APA(C)PA 可以被分解为两个元路径,即 (APAPA)和 (APCPA)。前者交换矩阵可由W_{AP}·W_{PA}·W_{AP}·W_{PA}
计算,第二个可由W_{AP}·W_{PC}·W_{CP}·W_{PA}。然后可以计算P3的交换矩阵C_{p_3}=W_{AP}·((W_{PA}·W_{AP})\odot (W_{PC}·W_{CP}))·W_{PA}。
基于语义结构实例的节点相似性SemSim:
SemSim通过结合多个元路径和元图来衡量两个目标节点之间的相似度。对给定的元路径和元图P=\{P_m\}^M_{m=1},这些元路径和元图都以目标节点类型 Lt开始和结束。对属于Lt的两个节点v_{ti}和v_{tj}之间的相似度定义如下:
其中\omega_m表示元路径或元图Pm的权重,\omega=[\omega_1,\omega_2,...\omega_M]是所有元路径和元图权重的可训练参数向量。即图中所示Weights。
另外SemSim是非对称的,即SemSim(v_{ti},v_{tj})\neq SemSim(v_{tj},v{ti})。且SemSim(v_{ti},v_{tj})\in [0,1],对自身的相似度是1。
SemSim通过计算基于多个元路径和元图的实例数量的加权平均值来衡量两个节点之间的相似度。
分子 2⋅CPm(i,j)计算了在元路径或元图 Pm下,节点 vti 和 vtj之间的实例数量的两倍。使用2倍是为了强调直接相连的节点对。
分母 CPm(i,i)+CPm(j,j)则是节点 vti和 vtj在元路径或元图 Pm下,它们各自与自身以及其他节点的实例数量之和,用于归一化处理,确保相似度量不会因节点的连接度不同而产生偏差。
卷积捕获节点间交互
D 是一个对角矩阵,D_{ii}=\sum_jA_{ij},W^{(l)}是第 l 层特定的可训练权重矩阵。σ(⋅) 是激活函数,例如 ReLU 或 Sigmoid。H^{(0)}=X是输入节点特征,H^{(l)}\in \mathbb{R}^{N×N}是第 l 层的输出节点特征
3.2 基于内容的子注意层CAL
CAL首先构造一个基于多语义结构的邻接矩阵,在图中表示为A',然后利用self-attention通过关注其邻居来计算每个节点的表示。
首先,对给定目标节点类型Lt开始和结束的元路径和元图的集合,构造邻接矩阵A' \in \mathbb{R}^{N×N},N代表类型Lt节点的总数。A'是二进制矩阵,并且只有当节点vti和节点vtj之间存在至少一个元路径/元图,A'_{ij}=1。 A'定义了其基于一阶语义结构的邻域N_i=\{v_{tj}|A'_{ij}=1\},且vti也在其领域内。
接下来,我们设计了一个注意力机制来对目标节点执行自注意力。掩码注意力主要关注由A'定义的领域。注意力定义为a : \mathbb{R}^{d'×d'}\rightarrow \mathbb{R},其中d‘是CAL的输出尺寸,a是具有非线性的单个前馈层。a将两个节点的线性变换作为输入,并输入注意力系数:
vti和 vtj 分别代表节点 vti和 vtj的输入表示。W是一个权重矩阵,用于将输入节点特征转换到更高层次的特征空间。a是一个权重向量。σ(⋅)表示非线性函数,∥表示连接操作。注意力系数 eij表示 vtj的表示对于 vti的重要性。
然后利用softmax进行归一化:
\alpha_{ij}是非对称的,然后使用归一化的注意力系数,关注其邻居v'_{ti}=\sigma(\sum_{v_{tj}\in N_i}\alpha_{ij}W_{v_{tj}})。再进一步使用多头注意力来稳定训练过程,得到公式:
\alpha^h_{ij}代表头部级别的归一化注意力系数,Wh 代表头部级别的线性变换矩阵,再设置每个头的输出维度为d'=d/H,以确保 CAL 的输出维度等于其输入维度。
3.3 高阶属性增强框架HAE
HAE由多个SCL和CAL共同组成框架。以阶数为4的HAE_{GNN}为例,包含四个组成层,即,一个SCL后接三个CAL。SCL通过元路径和元图中包含的丰富异构语义增强了初始BOW节点功能。之后,通过堆叠三个CAL,HAE_{GNN}^{4l}能够捕获基于一阶以及基于高阶语义结构的邻域之间基于内容的交互。
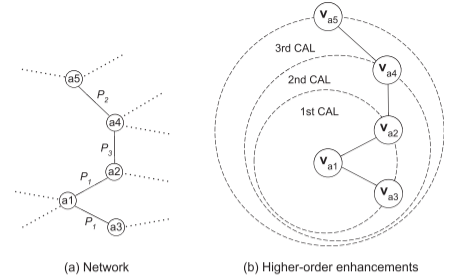 a1-a5是作者,P1-P3是语义结构
a1-a5是作者,P1-P3是语义结构
如图,以DBLP数据集为例,CAL通过嵌入作者的一级语义结构的邻居来增强作者的嵌入。最终,第一层CAL利用va2和va3强化va1,利用va1和va4强化va2。然后,第二个CAL重复此过程并使用va2提高va1。此时,第一个CAL已将va4强化到va2,因此第二个CAL间接地用va4强化了va1。