论文题目:Multimodal Commonsense Knowledge Distillation for Visual Question Answering (Student Abstract)
发表期刊:2025 AAAI Conference on Artificial Intelligence (AAAI)(CCF-A)
论文作者:Shuo Yang, Siwen Luo, Soyeon Caren Han
作者单位:墨尔本大学,西澳大学
1. 背景
1.1 问题
视觉问答(VQA)任务要求模型根据图像和问题生成准确的回答,通常需要结合视觉信息、语言信息和外部常识知识。现有的多模态大语言模型(MLLMs)和视觉语言预训练模型(VLPMs)在VQA任务中表现出色,但仍面临以下挑战:
常识知识依赖:许多VQA问题需要外部常识知识,而现有模型在生成高质量提示或处理常识知识时表现不足。
高计算成本:模型的微调和复杂提示生成需要大量计算资源。
1.2 本文贡献
论文提出了一种新颖的基于图的框架,通过整合视觉对象、问题和常识知识,结合图卷积网络(GCN)和知识蒸馏技术,提升VQA性能。
1. 提出了一种新颖的多模态常识知识蒸馏框架
该框架通过构建统一的关系图,将视觉对象、问题文本和外部常识知识整合在一起,并利用图卷积网络(GCN)进行关系学习。
框架设计灵活,可以适配任意类型的教师模型和学生模型,无需额外的微调。这种灵活性使得该框架能够广泛应用于不同的模型结构和任务场景。
2. 解决了现有模型的局限性
现有多模态大语言模型(MLLMs)和视觉语言预训练模型(VLPMs)在处理需要外部常识知识的VQA问题时表现不佳。本文通过引入外部常识知识(如ATOMIC2020数据集中的知识三元组),并将其嵌入到图结构中,显著提升了模型对常识性问题的理解能力。
直接微调大型视觉语言模型计算成本高昂,而本文提出的教师-学生知识蒸馏框架通过将知识从教师模型传递到较小的学生模型,避免了对大型模型的直接微调,显著降低了计算成本。
3. 提供了一种高效的多模态学习方法
通过GCN捕捉多模态输入之间的关系,并将常识知识注入到模型中。这种方法不仅能够有效整合不同模态的信息,还能通过关系学习提升模型的推理能力。
教师模型可以灵活地使用不同的预训练视觉和文本编码器进行特征提取,从而支持多样化的特征表示和模型结构。
2. 方法
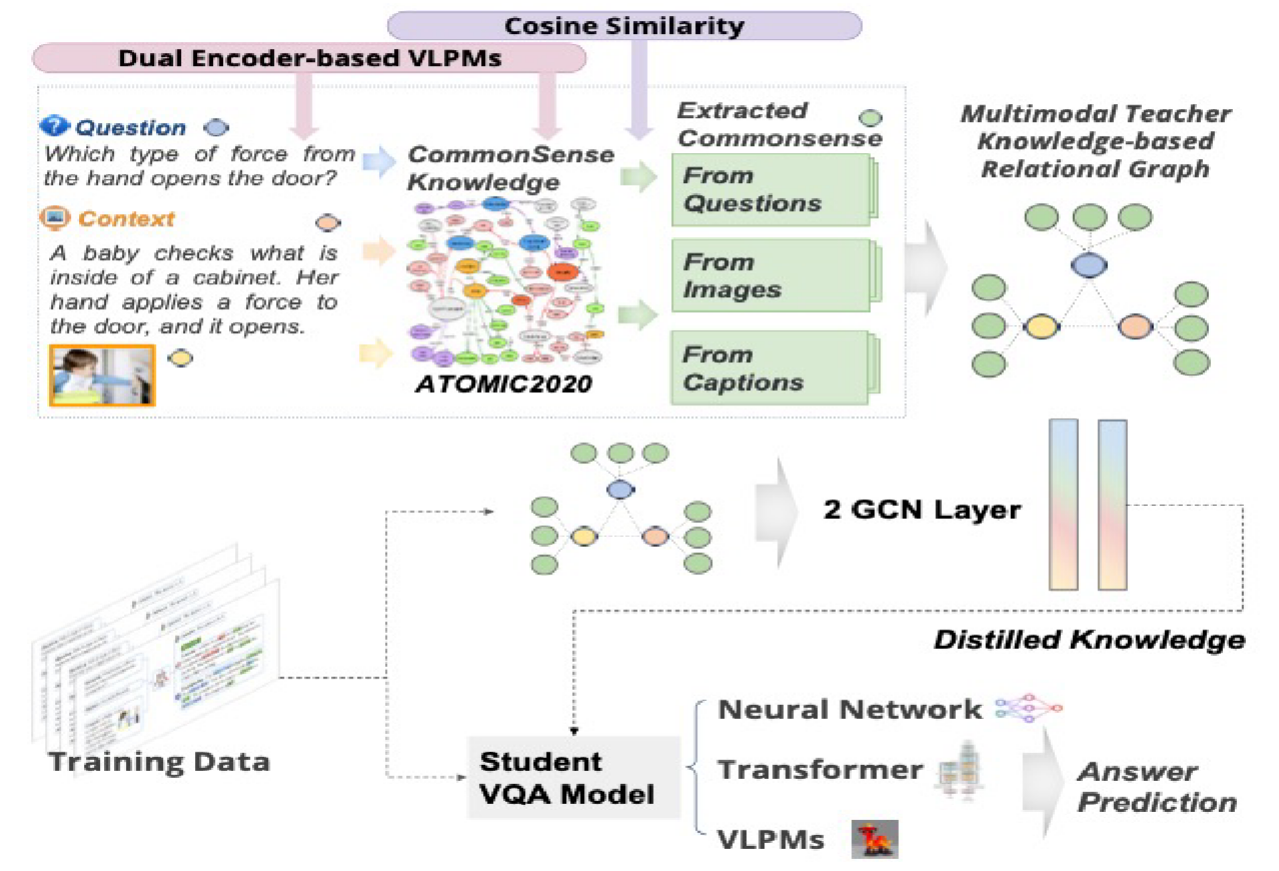
将输入表示为图,以捕获由常识知识丰富的不同模态之间的关系。
使用GCN来训练教师图模型。
将受过训练的教师所学的知识提炼到不同大小的学生模型中。
3. 图构建
该框架的核心是将视觉对象、问题和常识知识整合为一个统一的关系图,并通过图卷积网络(GCN)在师生框架下进行学习和知识蒸馏。具体来说,对于数据集中的每个样本,构建一个包含图像、问题和上下文信息的异构子图。子图中的节点分为两类:内容节点和常识节点。
内容节点:包括问题节点、语言上下文节点、视觉上下文节点和视觉-语言节点四种类型的节点。包括视觉对象(从图像中提取)和问题中的文本内容。这些节点通过双编码器视觉-语言预训练模型(VLPM)投影到一个共享的单模态嵌入空间,生成嵌入向量\mathbf{v}_s。
常识节点:从ATOMIC2020数据集中检索的与内容节点语义相关的常识知识三元组。
具体检索过程:
将ATOMIC2020数据集中的所有常识三元组预嵌入到与内容节点相同的共享嵌入空间,生成嵌入向量\mathbf{v}_k。
计算每个内容节点嵌入\mathbf{v}_s 与常识三元组嵌入\mathbf{v}_k 之间的余弦相似度:
\operatorname{sim}(V_s, k) = \frac{\mathbf{v}_s \cdot \mathbf{v}_k}{\|\mathbf{v}_s\|\|\mathbf{v}_k\|}
对于每个内容节点V_s,选择余弦相似度最高的K 个常识三元组(实验中设置K=3)作为常识节点V_k,并将其添加到子图中。
边:节点之间的边通过余弦相似度和互信息(PMI)定义,以捕捉节点之间的语义关系和统计依赖性。
边通过以下两种度量定义:
余弦相似度:基于节点嵌入向量之间的相似性,反映语义相关性。
点互信息(PMI):基于统计依赖性,捕捉节点间的共现关系。
这些边的引入使图能够表示多模态信息之间的复杂关系,例如视觉对象与问题之间的关联,或视觉对象与相关常识知识之间的联系。
最终得到每个样本对应的子图,每个子图包含与特定VQA问题相关的视觉对象、问题文本和检索到的常识知识。每个子图是一个统一的关系图,通过节点和边整合了多模态信息,为后续的图学习提供了结构化表示。
4. 图学习
图学习利用图卷积网络(GCN)对构建的关系图进行处理,捕捉节点之间的多模态信息和常识知识的关系。图学习过程分为以下步骤:
使用一个标准的两层GCN来聚合和更新图中节点的特征。GCN的计算公式为:
其中:
f(V)^{(l)} \in \mathbb{R}^{N \times T^{(l)}}:表示第l 层节点的特征矩阵,$N$ 为子图中节点数量,$T^{(l)}$ 为特征空间维度。
\hat{A} = A + I_N \in \mathbb{R}^{N \times N}:图的邻接矩阵A 加上自连接(单位矩阵I_N),确保节点自身信息被考虑。
\hat{D}:度矩阵,用于归一化邻接矩阵,计算方式为\hat{D}{ii} = \sum_j \hat{A}{ij}。
\sigma^{(l)}:第l 层的激活函数(如ReLU),用于引入非线性。
W^{(l)}:第l 层的可学习权重矩阵,用于特征变换。
GCN通过聚合邻居节点的特征,更新每个节点的表示,从而捕捉图中节点间的关系。
对每个子图的节点特征进行平均池化操作,将节点特征矩阵降维为一个固定维度的向量:
池化后的向量表示整个子图的综合特征,融合了视觉、文本和常识信息。
多层感知机(MLP):
将池化后的嵌入输入一个MLP,映射到分类空间:
其中M 为子图数量,T^{(O)}为唯一标签(答案类别)的数量。
MLP生成最终的分类预测,用于回答VQA问题。
5. 知识蒸馏
知识蒸馏用于将教师模型的常识推理能力传递给学生模型,使其在较低计算成本下保持高性能。过程如下:
5.1 师生框架
教师模型:
基于GCN的图模型,经过图学习训练,具备强大的多模态和常识推理能力。
教师模型生成软标签(soft labels),即通过softmax函数得到的概率分布: Pj=softmax(Tj(X))其中T_j(X) 为教师模型对输入X 的输出。
学生模型:
可以是任意类型的模型(如MLP、Transformer或VLPM),通过蒸馏学习教师模型的输出分布: Ps=softmax(S(X))其中S(X) 为学生模型的输出。
5.2 蒸馏损失
使用Kullback-Leibler散度(KLDivLoss)优化学生模型,使其输出分布接近教师模型的软标签:
其中n_T 为教师模型数量(若为单一教师,则n_T=1)。
KL散度衡量学生模型输出分布与教师模型输出分布之间的差异,鼓励学生模型学习教师模型的概率分布,从而继承其常识推理能力。
5.3 整体损失
学生模型的优化目标结合了学生交叉熵损失(直接监督)和知识蒸馏损失:
学生交叉熵损失(\mathcal{L}_{SCE}):确保学生模型直接学习真实标签。
知识蒸馏损失(\mathcal{L}_{KD}):使学生模型模仿教师模型的软标签,增强其泛化能力和常识推理能力。
通过联合优化,学生模型在保持低计算复杂度的同时,获得了教师模型的强大推理能力。
6. 实验
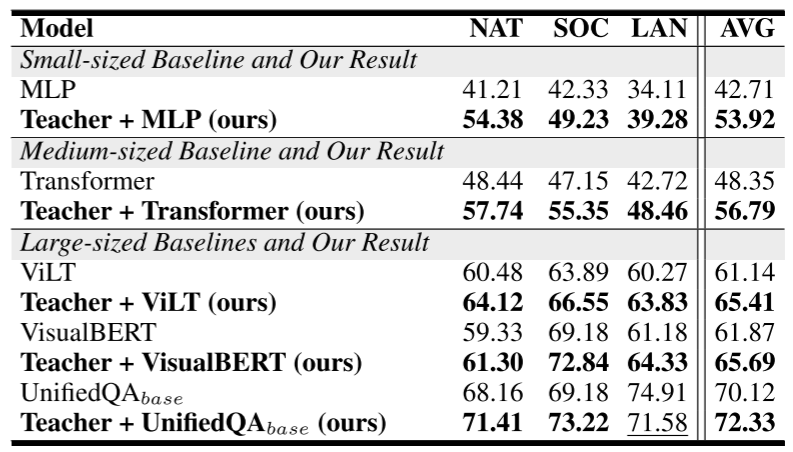
在ScienceQA上的整体表现。问题类:NAT =自然科学,SOC =社会科学,LAN =语言科学。
本文将Micro-F1评分与三种不同大小的基线模型进行了比较:(1)小型MLP;(2)中型Transformer;(3)在ScienceQA数据集中应用的三种大型VLPM:(a)VisualBERT(Li等人,2019):通过BERT式架构集成了基于RoI的视觉特征和基于令牌的文本特征。(b)ViLT(Kim,Son,and Kim 2021):直接使用统一的融合编码器处理视觉和文本标记。(c)UnifiedQA(Khashabi et al. 2020):在一个纯文本模型中统一了各种QA格式。
从表所示的整体性能中,可以看到,采用提出的框架后,他们的平均得分有了显著提高,分别提高了11.21%和8.44%。对于大型VLPM,尽管它们非常复杂,但它们的性能有了显著的提高。
7. 讨论
未来可以做的创新:
论文中使用固定数量(K=3)的常识知识三元组来增强子图。未来是否可以引入动态选择机制,根据问题和图像内容的复杂性来选择不同数量或类型的常识知识(当然 这个同时涉及到了动态图的生成学习过程),可以设计一种检测和过滤无关常用知识三元组的方法。
是否可以探索多层级的图结构,将视觉对象、问题和常识知识分别建立独立子图,再通过跨图注意力或者消息传递机制进行融合以捕获不同模态之间的复杂关系。
可以尝试使用异构的图神经网络,为不同类型的节点分配不同的权重,提升多模态的建模能力。
在知识蒸馏方面,是否可以结合不同模态的教师模型,以提升整体的泛化性能。